
技术路径a开发指南
各阶段数据库构建
如图所示,对于一条原文本,通过关键词筛选系统的处理,我们可以得到如下格式的json文件
1
2
3
4
5
6{
"准备阶段": ["公司以诈骗为目的,冒充正规机构"],
"事前阶段": ["通过虚假宣传吸引客户"],
"实施阶段": ["使用欺骗手段与客户沟通", "伪造身份信息", "诱导客户购买服务或产品"],
"事后阶段": []
}这部分开发人员的工作很简单:
为了方便对接主程序,开发人员采用只有10条(即10个案子)如上
json格式数据的一个记录各阶段关键词的json文件。
比如这样的文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21[{
"准备阶段": ["公司以诈骗为目的,冒充正规机构"],
"事前阶段": ["通过虚假宣传吸引客户"],
"实施阶段": ["使用欺骗手段与客户沟通", "伪造身份信息", "诱导客户购买服务或产品"],
"事后阶段": []
},
{
"准备阶段": ["公司以诈骗为目的,冒充正规机构"],
"事前阶段": ["通过虚假宣传吸引客户"],
"实施阶段": ["使用欺骗手段与客户沟通", "伪造身份信息", "诱导客户购买服务或产品"],
"事后阶段": []
},
{
"准备阶段": ["公司以诈骗为目的,冒充正规机构"],
"事前阶段": ["通过虚假宣传吸引客户"],
"实施阶段": ["使用欺骗手段与客户沟通", "伪造身份信息", "诱导客户购买服务或产品"],
"事后阶段": []
}
]这些少量数据只是作为例子,测试你编写出来的
python脚本可不可以把该文件中所有”准备阶段”、”事前阶段”、”实施阶段”、”事后阶段”,分别提取出来,让属于同一阶段的关键词在同一组。参考我的思路,使用
csv格式文件储存这些关键词:1
2
3
4准备阶段,事前阶段,实施阶段,事后阶段
冒充正规机构,通过虚假宣传吸引客户,诱导客户购买服务或产品,注销相关账号
xxxx,xxxx,xxxx,xxxx
......正如我数据集的格式:
LLM总结各阶段关键词
- 首先遍历该csv文件中的各列关键词,对海量数据通过相似性去重,获取相似性最低的一组数据,将这组数据放入对应的数据库中,获取4个分别储存已清洗数据的数据库,使用
python脚本分别将四个数据库中的关键词进行提取后通过langchain自带的RunnablePassthrough类导入预设好的LLM提示词中。 - 通过链式输出获取LLM基于对应阶段关键词对对应阶段的总结文本,将该文本存于变量中。
- 通俗来说,就是把每个阶段的关键词,喂给LLM进行总结,输出对该种案件的该阶段有逻辑性的描述、总结,再将该逻辑性总结描述文本再次传入LLM中获取犯罪脚本。
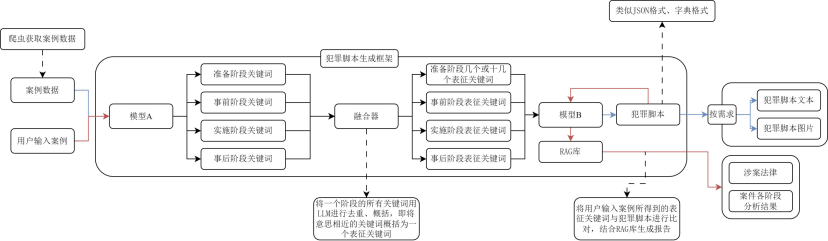
- 流程图如下:

再次传入LLM大模型中获取犯罪脚本
- 将存有LLM基于对应阶段关键词对对应阶段的总结文本的变量作为嵌入犯罪脚本输出模型的提示词中,设置提示词,让模型输出犯罪脚本文本形式以及表格形式。
- 将两种呈现形式的犯罪脚本分别存于储存图形、文本形式的犯罪脚本数据库中,完成工作。
该开发路径的流程图:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Dedsec的博客!



